A Story About Pizza and Hamburgers

Imagine your training set: six images of pizza, two images of hamburgers. You train a model. The reported accuracy is 75%.
You go to celebrate. Then you actually run the model. You feed it a picture of a pizza — it correctly says "pizza." You feed it a picture of a hamburger — it confidently says "pizza." You feed it a third picture of anything — "pizza."
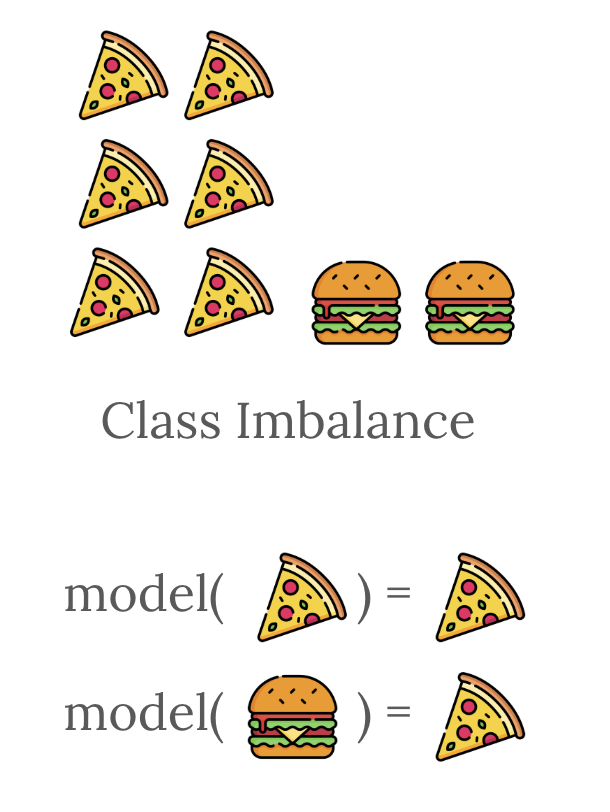
The model has learned exactly one thing: pizza is more common than hamburgers. By predicting "pizza" every single time, it gets six out of eight examples right. Seventy-five percent accuracy. The accuracy is technically true. The model is useless.
In High-Stakes Domains
A healthcare diagnostic where 99% of patients are healthy: a model that predicts "healthy" for everyone scores 99% accuracy and detects no one who's actually sick. Fraud detection. Defect detection. Rare event prediction. Whenever your outcome is rare, accuracy as a sole metric is a trap.
Here's a personal story. I lost a hackathon over this once. I'd adjusted for class imbalance — my model was learning to discriminate the minority class properly, and my accuracy came in around 92%. The team that won didn't adjust. Their model essentially predicted the majority class every time and got 99.5% accuracy. The judges scored on accuracy alone, and that was that. Their model was technically the "winner" and operationally worthless. It has stuck with me ever since as a reminder that imbalanced data plus the wrong metric is a recipe for impressive-looking models that don't actually work.