Vector Databases and RAG
Five years ago, "vector database" didn't exist as a product category. Today it's in every AI job description. Understanding why requires understanding what embeddings are — and that's worth doing carefully, because the concept is genuinely elegant.
A vector embedding is a list of real numbers that represents a piece of content — a word, a sentence, an image, an audio clip — in a high-dimensional space. The useful property is this: semantic similarity becomes geometric proximity. Things that mean similar things end up near each other in that space.
The classic demonstration comes from word2vec, an embedding model trained on text in 2013. If you take the vector for "king," subtract the vector for "man," and add the vector for "woman," you get a vector that is closest to "queen":
Embedding Arithmetic
This works because embeddings are trained to place words used in similar contexts near each other. "King" and "queen" appear in similar sentence structures; so do "man" and "woman." The difference vector encodes the concept of gender.
Modern embeddings come out of transformer models, with typical embedding sizes ranging from 512-3072. Whatever the dimensionality, the storage problem is the same: you need a database that can hold millions of these vectors and answer the question "find me the most similar to this query vector" in milliseconds.
That's what vector databases do. Pinecone, Weaviate, Milvus, Chroma, and the pgvector extension for Postgres all implement some variant of approximate nearest-neighbor search — an algorithm that finds the closest vectors without comparing against every vector in the database.
Nearest-Neighbor Search
The similarity metric most commonly used is cosine similarity — the cosine of the angle between two vectors:
A value of 1 means the vectors point in the same direction (maximally similar). A value of 0 means they're perpendicular (orthogonal/unrelated). A value of −1 means they point in opposite directions.
Algorithms like HNSW (Hierarchical Navigable Small World graphs) and IVFFlat allow approximate nearest-neighbor search at scale — finding the closest vectors quickly without an exhaustive scan.
The most prevalent application of vector storage right now is for Retrieval-Augmented Generation (RAG). If you've used an "AI chatbot for our docs" product — a customer support bot, a document Q&A system, an internal knowledge assistant — you've almost certainly used RAG. We will provide a brief introduction here. We will dive into the details in Deep Learning next semester.
The RAG Pattern
- 1. Take your private knowledge base — your company's docs, your product catalog, your internal wiki — and split it into chunks.
- 2. Embed each chunk into a vector using an embedding model. Store the vectors in a vector database alongside the original text.
- 3. When a user asks a question, embed the question with the same embedding model.
- 4. Query the vector database: find the chunks most similar to the question vector.
- 5. Stuff those chunks into the LLM prompt as context: "Given the following documents, answer the question..."
- 6. The LLM answers — grounded in your data, not its training data.
LLMs are trained on public data with a knowledge cutoff. They don't know what's in your internal docs, your proprietary research, or anything that happened after their training ended. RAG solves this without fine-tuning, at a fraction of the cost.
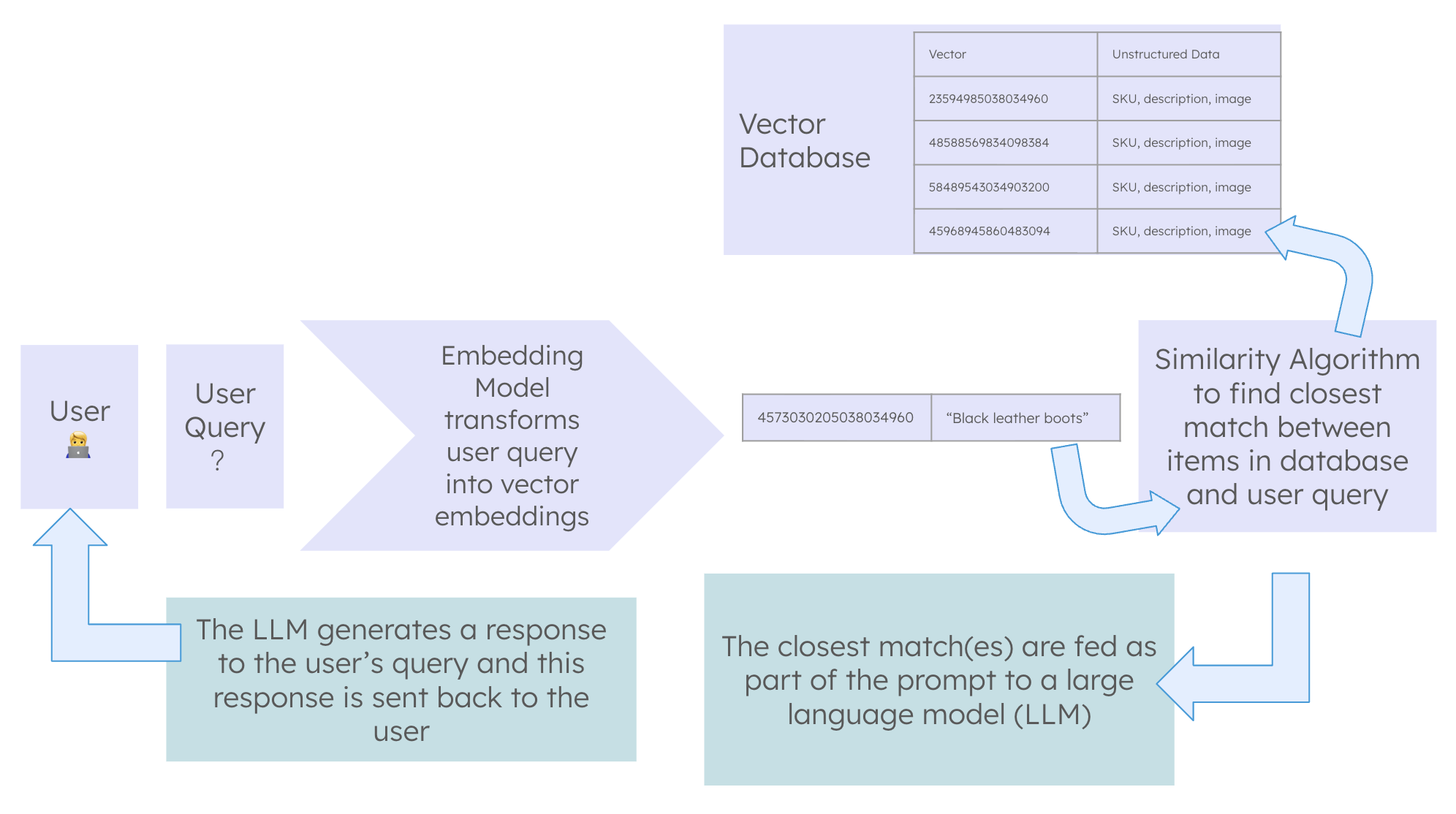
The Bottleneck Is the Vector Database, Not the LLM
After building multiple RAG systems, the consistent finding is: the quality of answers is almost entirely determined by the quality of what's in the vector database. A powerful LLM can't answer a question if the relevant chunk wasn't retrieved. If the chunking strategy is wrong, if the embedding model doesn't capture the domain well, or if the retrieval step returns irrelevant context, the LLM will hallucinate or hedge. Invest in the data layer, not just the model layer.
A legal tech company wants to build an AI assistant that can answer questions about their clients' specific contracts — documents that were created after any LLM's training cutoff and contain proprietary information that should never leave the company. Which approach best fits this requirement?