Text
In computer vision, every pixel cleanly converts into three numbers: red, green, blue. Language is a little harder to convert into numbers...
Consider the word bank.
- "bank of the river" — a little hill next to a river.
- "deposited money at the bank" — a financial institution.
Same string of four letters, completely different meaning. Ideally we want to represent these as different numbers, because they really are different things. This is the homonym problem, and it's everywhere in language.
Now flip it. "Sneakers," "running shoes," and "tennis shoes" all refer to the same physical object in everyday speech. Synonym problem. How do we encode them in a way that captures that they mean the same thing without manually building a thesaurus?
And then there's the fact that observations are not independent. "The dog ate the bone. It tasted good." What is "it"? You can only answer because you read the previous sentence. History matters.
Tokenization
The first step in any text --> number conversion is tokenization. Tokenization splits a string into substrings. The default is to split on whitespace and punctuation:
"Which class is the best class at Duke? Deep Learning Applications."
becomes
['Which', 'class', 'is', 'the', 'best', 'class', 'at', 'Duke', '?', 'Deep', 'Learning', 'Applications', '.']You can also tokenize by sentence (useful for long documents you want to summarize one sentence at a time), by subword (the modern default — tokenization → ['token', 'ization']), or by character (rarely useful, but possible).
Split on whitespace and punctuation. Simple and fast — but out-of-vocabulary words get a single <UNK> token.
Split words into meaningful sub-pieces. Handles new words gracefully: 'tokenization' → ['token', '##ization']. Used by BERT, GPT, and most modern models.
Every character is its own token. No unknown tokens ever, but sequences are very long and the model must learn to combine characters into meaning.
Type any sentence and compare word-level, subword, and character-level tokenization side by side.
Stop Word Removal
Many common words — the, of, and, is — appear so frequently that they swamp the signal in your features. Stop word removal drops them so the model can focus on what carries meaning.
NLTK ships with a default English stop word list, but you can absolutely add to it. If you're classifying product reviews, the word "product" is technically informative but in practice useless, since it appears in every document. Add it.
Apply stop word removal to our example tokens and watch what gets stripped:
Tokens struck through in red are NLTK stop words. The filtered list keeps only content-bearing words.
Stemming vs. Lemmatization
The words branch, branches, branching, branched all refer to roughly the same concept. We'd like to collapse them.
- Stemming chops off suffixes mechanically. changes, changed, changing →
chang. Not a real word. Doesn't matter — it's a feature, not a noun. Fast, crude. - Lemmatization uses a dictionary to map each form to a canonical root. is, am, were →
be. changes →change. Slower, but the output is always a real word.
If you're throwing together a quick keyword classifier on millions of documents, stem. If you care about interpretability or accuracy, lemmatize.
Embedding Models
Over the decades, we have experimented with many modeling techniques to turn tokens of words into numbers. From Bag of Words to Word2Vec to modern transformer approaches, you will cover these in great detail in Deep Learning. For now, we will abstract away the architectures and focus on the concepts. Embedding models are neural network based models that allow us to take words and convert them into numbers. Attention-based embedding models enable us to do this extremely well due to the attention mechanism (you will also learn a lot more about this later).
Nearest neighbors to king
Similarity = cosine similarity in 2D projection. Click any word to explore its neighbors.
Explore a pretrained Word2Vec embedding space. Word2Vec is a simple but powerful neural-network based embedding model. Search for a word and see its nearest neighbors. Try words with multiple meanings.
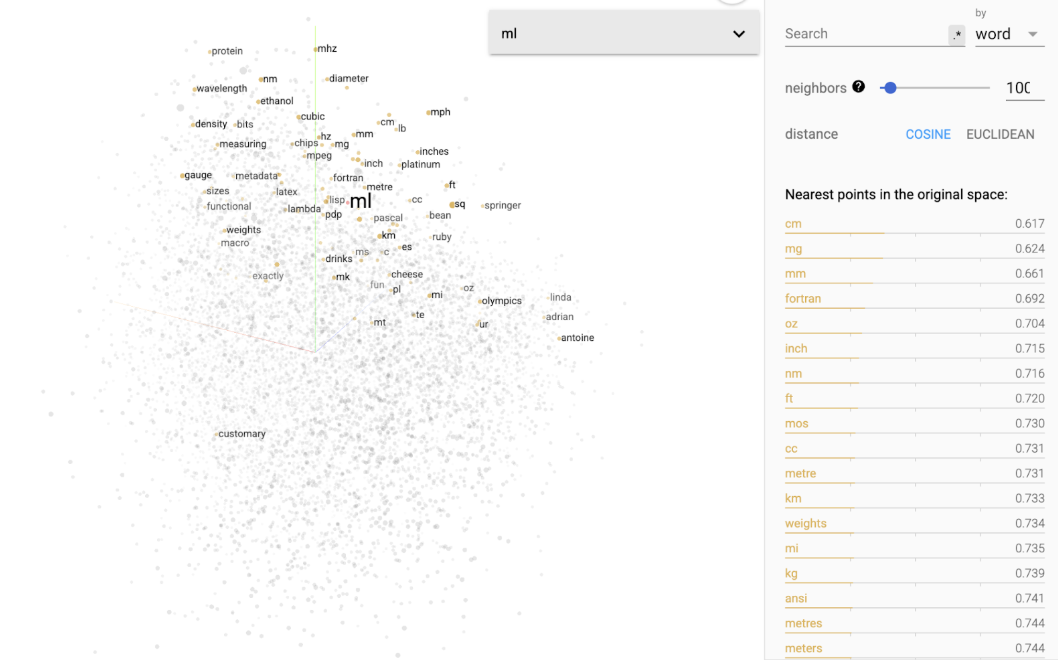
Word2Vec assigns a vector to each word. What property of those vectors makes them useful for downstream ML tasks?