Transparency, Interpretability, Explainability
These three terms get used interchangeably. They mean different things, and the distinction matters — especially as regulation increasingly demands them.
Transparency is about documenting the system. Model architecture, training data, optimization procedure, source code access, data sheets. It enables verification, validation, accountability, and compliance. Transparency is what makes the other two possible — you can't interpret or explain a system whose internals are secret.
Interpretable Machine Learning uses models that are inherently understandable. Decision trees you can trace through. Linear regression with examinable coefficients. Generalized Additive Models (GAMs). The model itself doesn't need additional explanation — the model is the explanation. Interpretable models are often preferred in regulated domains (medicine, finance, criminal justice) where the decision process must be auditable, not just the outcome.
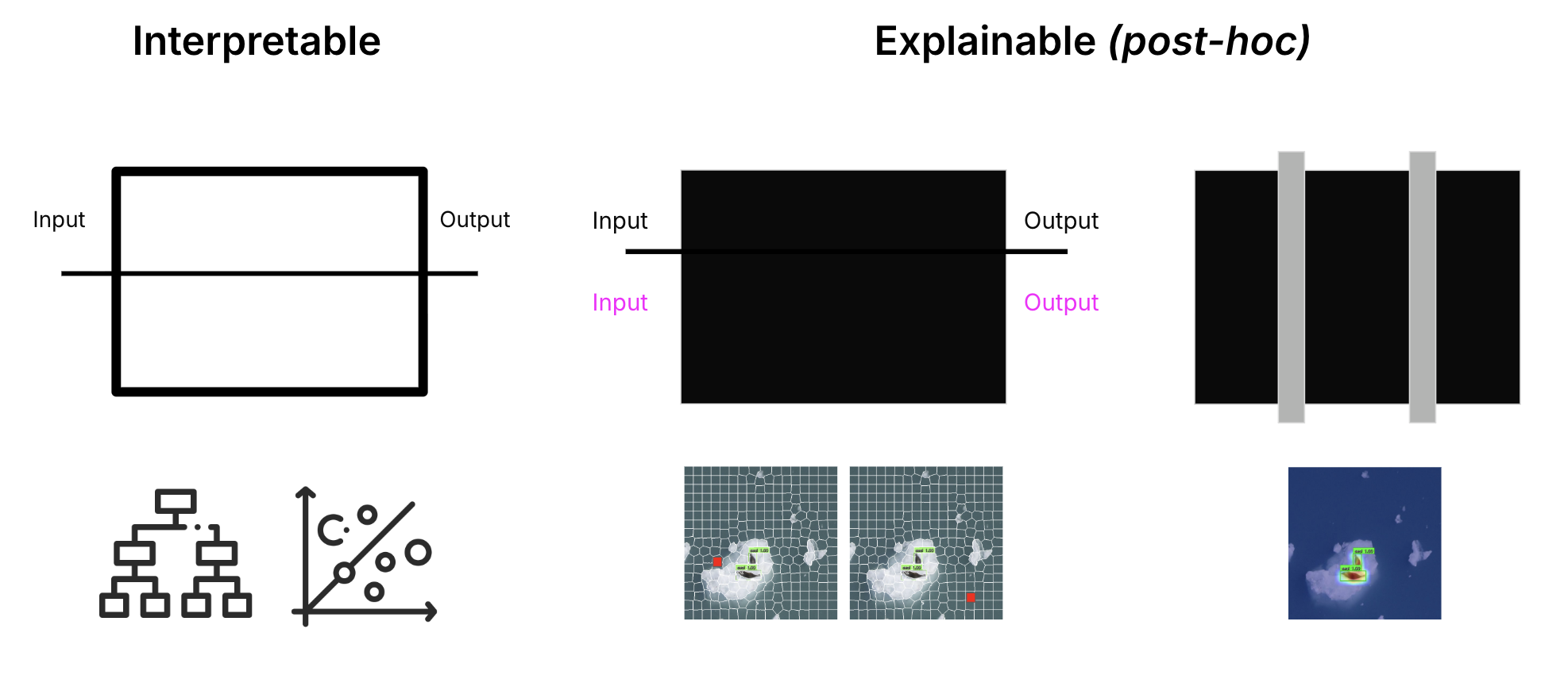
Explainable AI (XAI) is used for black-box models where the internal mechanism is too complex to inspect directly. XAI methods try to approximate the model's reasoning post-hoc:
- SHAP — game-theoretic feature attributions showing each feature's contribution to a specific prediction.
- LIME — local linear approximations of model behavior around a specific prediction.
- Counterfactual explanations — "what would have had to be different for the outcome to change?"
- Saliency maps — for images, highlights which pixels most influenced the prediction.
Regulation Is Arriving
The EU's AI Act has explainability requirements for high-risk systems. US financial regulators require lenders to explain credit decisions. As AI expands into regulated domains, explainability is moving from a research interest to a compliance requirement. If you go into industry, this is a skill worth developing now rather than when the regulation lands on your desk.
A bank uses a deep neural network to make loan decisions. A regulator requires that denied applicants receive an explanation of why they were denied. The bank's ML team uses SHAP to generate post-hoc explanations. Is this transparency, interpretability, or explainability — and is it sufficient?